AI, ML models, and data ethics

There is definitely no better way to spend Christmas than to look at AI progress and, in particular, gain forecasting capabilities from trend extrapolation. The definition of “fermiized” is breaking concepts down into sub questions for which more rigorous methods can be applied. For example, Bayesian reasoning and Bayesian calculations are computing probabilities after breaking them down into more manageable parts. I will fermiize AI progress.
AI and Compute
Three factors drive the advance of AI: algorithmic innovation, data, and the amount of compute available for training. What I gathered was that the compute does not equate to direct usefulness or direct constraint on performance. Important breakthroughs are still made with modest amounts of compute.
My summary of Srivastava's DropOut paper
Deep neural networks are powerful tools with many parameters, but the machine learning system can be laborious and slow to use. This is due to units co-adapting and the difficulty in integrating lots of neural nets at a time, even considering a model with a couple hidden layers. Dropout is a technique that can be used to reduce loads on these network systems. The general premise is that hidden and visible units within the network can be randomly “dropped” from the system for given iterations of a given network run over many unique randomly dropped iterations. The “simplified” resulting conclusions can then be averaged to give an approximation for the result of the entire network as if it was done without any dropout. This approximation can be done assuming that each simplified derived result is part of an equally weighted mean of the end prediction. The benefits include exponentially fewer computations while also being able to use limited or incomplete data sets in these deep neural networks.
My summary of the Adam Optimizer paper
Objective functions are functions that are taken in machine learning, especially in deep learning, to be optimized with respect to parameters. Knowing that a learned optimizer can follow the gradient descent method to follow a path from initial condition to the global/local minimum, and knowing that first-order derivative is best suited for optimization, we understand that Adam performs optimizations of randomly distributed objective functions.
Adam combines current AdaGrad and RMSProp methods, which stores an exponentially decaying average of past squared gradients, and also stores the past gradients. The "Adaptive" feature in Adam is using these two respective moments, where the second moment helps label learning rates for different parameters.
The algorithm requires user-defined stepsize, exponential decay rates for moment estimates, the objective function and parameters and the init. parameter vector. The estimates are then bias-sifted and computed until convergence. The researchers tested logistical regression across multiple methods with the MNIST dataset (also MNIST multilayer neural network + dropout), and Adam performed with lowest training cost, and converges much faster.
My selected ML models
The list of Machine Learning models that we will examine are:
The Perceptron/ Mark I Perceptron
Digit Classifier (LeNet)
Image Classifiers Section
AlexNet
VGG 19
ResNet
CLIP
Language models Section
Generative Pre-trained Transformer (GPT)
GPT-2
GPT-3
BERT
Game-Playing AI section
AlphaStar
AlphaGo
AlphaZero
MuZero
AlphaFold
Gato
DALL-E
PaLM
The Perceptron/ Mark1 Perceptron
1958
Frank Rosenblatt’s single-layer perceptron, or single-layer neural network, was implemented in 1958. The linear classifier is the first of many feedforward neural networks, with features like the feature vector and corresponding weights. Here we do not reference multilayered neural networks.

Function & Task
As a linear binary classifier, the Mark1 perceptron is capable of distinguishing, or “classifying” hundreds of pixels in front of the perceptron’s camera to be 0 or 1 depending on whether a colored square appeared on the right or left side of the canvas. It conducts on the basis of geometric similarities and differences. The first perceptrons also could classify images, for example, it could distinguish a man from a woman and one alphabet letter from another alphabet letter.
Image Classifiers Section
Digit classifier trained with MNIST dataset
1989
The digit classifier is an image classification model, also categorized as a convolutional neural network. It takes in a public MNIST dataset from the Keras library, with 70,000 total greyscale images representing handwritten digits from 0 to 9 with 28x28 pixels. The model architecture has a baseline model that has a single convolutional layer and 32 filters (or nodes), finally pooling after applying weights in the max pooling layer. A critical shortcoming of the digit classifier would be the confounding nature of “flattening” the images, the spatial distribution is lost. The current model achieves a classification accuracy of above 99%, an error rate between 0.4 and 0.2.
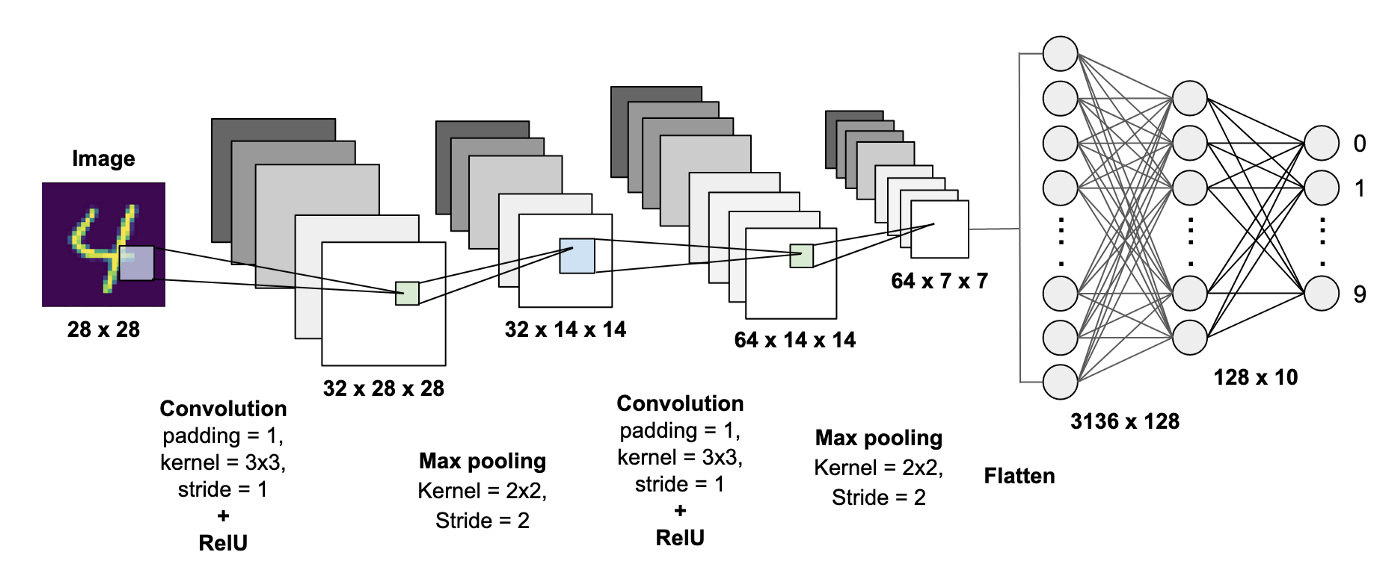
Function & Task
Yann LeCun’s digit classifier was first implemented for zip code recognition. The MNIST dataset is even more so the standard dataset for deep learning and computer vision. According to Christian’s The Alignment Problem, this model also cashed checks in ATMs— by the 1990s, LeCun’s networks were processing 10 to 20% of all checks in the United States.
AlexNet
2012
In 2006, Fei-Fei Li created a catalog of computer vision training data. What started as an “image atlas of concepts” with 500 to 1000 images per concept quickly changed into ImageNet, which was composed of 14,197,122 human-annotated images. In 2010 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) prompted researchers to submit algorithms that accurately identified objects and classified images. Scaling large inputs from the ImageNet database, AlexNet was the contest winner of ILSVRC.
AlexNet’s excelling feature[note]“quote from source that says things to backup your claim” quote[/note] was the splitting of the network into two— because GPUs at the time were limited to 3 gigabytes— which helped significantly its training module. Another feature of AlexNet was the use of a 0.5 dropout rate, as this will reduce the tendency to overfit. Overfitting means to pay special attention to external noise or converge too quickly. But it doesn’t come without a cost: the model’s training time is doubled.

Function & Task
AlexNet is an image classifier. It has been used commercially for sports field shots, i.e., classifying the shots into long, medium, close-up, and out-of-the-field shots.
Since the publication of AlexNet, many more computer vision related papers have been using GPUs and CNNs (and especially the usage of the ReLU activation function), citing Krizhevsky’s work.
VGG-19
2014
Visual Geometric Group-19 was the successor of VGG-16, both of which are one of the first image classifiers that used transfer learning. Transfer learning is the process of running a previous dataset on the model and the model retaining the learned knowledge, such that the learned knowledge can be applied to a new dataset. In this way, models are called “pre-trained”.
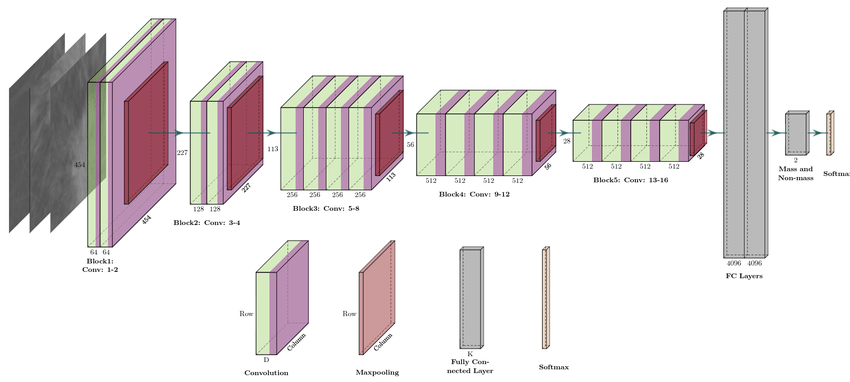
Function & Task
VGG-19’s transfer learning method has wide applicabilities such as disease prognosis in X-ray scans, malware detection, workers with/without masks detection. These publications all show novel modifications of the original VGG-19 framework (changing hyperparameters).
ResNet50
2015
It has been established that increasing the number of layers in a neural network does not entirely correspond to a higher testing accuracy, even without considering the vanishing gradient or the exploding gradient problem. This means that as the network depth increases, accuracy gets more and more saturated and then degrades. For example, the ResNet paper compares the 56 layers neural network with that of the 20 layers, and we note both a higher training and testing error in th 56 layers one.
Functionality-wise, as an ImageNet pre-trained convolutional neural network, ResNet50 can classify images from 1000 object categories. It is a model with 50 layers, hence the name, ResNet50. Structurally, the model has five stages each with a convolution block and an identity block, each convolution block has 3 convolution layers and each identity block has 3 convolution layers.
The main feature of ResNet50 is its pioneering lead in Residual Learning. The idea is that instead some layers can “skip” and feed into other layers using skip connections farther in the network. The layers that are most helpful to skip are the layers that do not add value to overall test accuracy. ResNet50 was the first image classifier model that used this feature. The paper states that the ResNet50 model has a top 1 error of 20.74% and a top 5 error of 5.25%.

Function & Task
The scalability threshold was expanded upon the introduction of Resnet— it is apparent that we can indeed train a computer vision model that is 150+ layers deep with an incrementally decreasing amount of error.
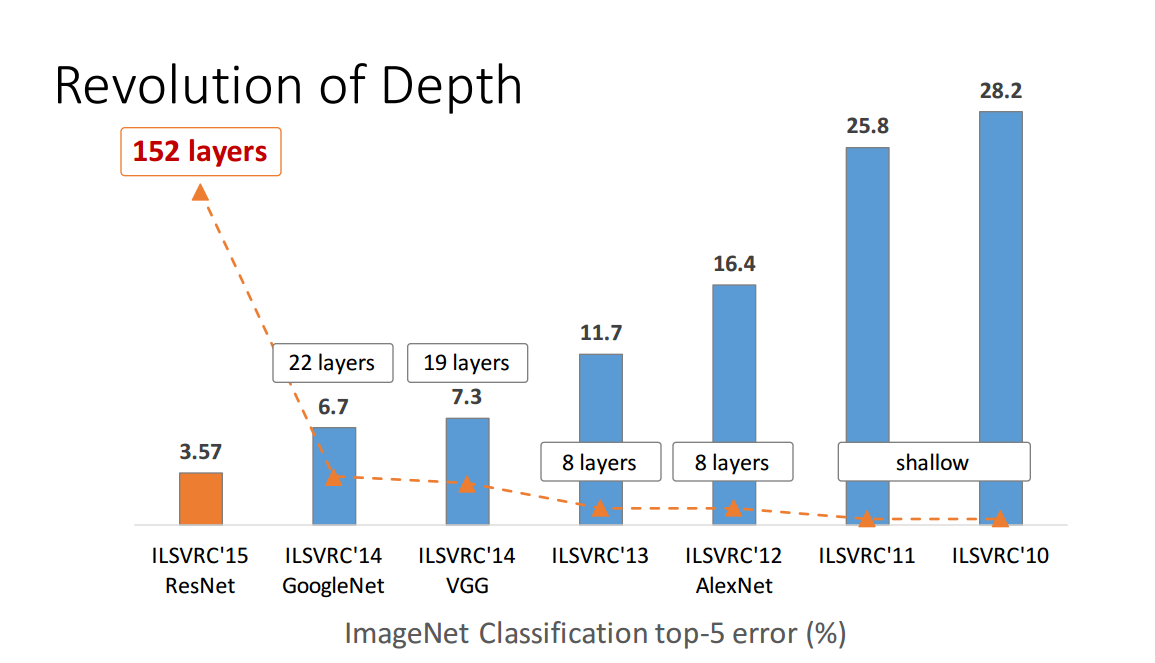
Figure 1. A list of ILSVRC model submissions and their layers count
For reference, the winner of ILSVRC 2015 was ResNet152, with 152 layers as opposed to the 2012 winner's 8 layers.Contrastive Language-Image Pre-training (CLIP)
2021
OpenAI launched CLIP in February 2021. It is a model that solves problems like insufficient vision datasets and has the ability to “adapt” to a new task without additional training examples.
Furthermore, a previous publication has identified that deep neural networks (DNN) sometimes have lower classification accuracy than humans when it comes to distorted images. Noisy and blurry images present a significantly harder task to the DNN than the human visual system, which suggests there is a different internal processing representation of these distorted images. This is a problem that CLIP was also able to solve.
As a zero-shot model, CLIP meets numerous benchmarks without exactly finetuning for “meeting those classification benchmarks”. Zero-shot means that the model can infer a specialized task, in particular, one that it is not trained to perform. For example, one-shot means that the model is given one example before it is asked to perform its task. The method that CLIP uses is feeding text-image data pairs, which is then given a training task of identifying which of 32,768 sample text snippets a given image belongs to.
CLIP’s distinguishing feature is its ability to lower compute using a contrasting objective. A contrasting objective is essentially what the name suggests— we contrast image samples. Similar image samples are clustered in the embedding space after loss minimization.
Function & Task
CLIP is capable of conducting fine-grained object classification, or subordinate concept level classification. Fine-grained object classification means being able to categorize subobjects within a class, e.g., rather than having a single label ‘bird’ for all bird species, it can categorize types of birds. CLIP being able to geo-localize means it can know where an image was captured. It is also able to perform Optical Character Recognition (OCR) at high accuracy.
Language Model Section
Bidirectional Encoder Representations from Transformers (BERT)
2018
BERT is a transformer language model developed by Google, with an architecture almost identical to that of the original transformer. There is subsequently a BERT Large model that has a parameter size of 340M, here we refer to BERT base.
A particular feature of BERT is next sentence prediction (NSP). Almost half of the model training is dedicated to this feature— therefore it is optimized for prediction.
Function & Task
BERT is able to conduct sentiment analysis, which is to discern positive and negative connotations. It can conduct chatbot conversations, predict text by the never-before seen Masked Language Modeling (MLM) method, generate text given keywords, understand context, and parse and summarize a long document. Another feature of BERT is the ability to perform Named Entity Recognition (NER), which is annotating words in a sentence with the entity it belongs to. For example, if a sentence is “Palpatine is eating some flan”, then Palpatine will be associated with the entity ‘person’ and flan will be associated with the entity ‘food’.
Currently, there are different domains as to where BERT is being used. This is referring to BioBERT, finBERT, and patentBERT which are models adopted from BERT that are traversing the biomedical corpus, financial corpus, and patent corpus.
Now, almost every English Google search query is processed by BERT.

Generative Pre-trained Transformer (GPT)
2018
Natural Language Processing (NLP) is a branch of AI where machine learning algorithms enable the interpretation and production of rule-based human language. Being a cross of linguistics and computer science, some NLP tasks include but are not limited to information retrieval, sentiment analysis, machine translation, and question answering.
Some examples of the first NLP models are: Bag of Words (BOW) model, TF-IDF model, Word2Vec. Open AI’s first GPT model was established on the basis of these precedents— evaluating given text data, weighing words by relevance, and clustering words by similarity in English. The paper published in 2018 detailed the model’s pre-trained dataset called BookCorpus, which is a collection of 7000 unpublished books. The model is tasked with both text prediction and text classification.
A transformer-based encoder-decoder model is important for our discussion of GPT-1, GPT-2, and GPT-3. An encoder takes the input and make it into a more intelligible format such as a vector, a map, or a tensor. The information is now extracted from the input and is often referred to as a feature matrix or feature vector. Then, the decoder receives the processed representation and changes it back to a sensical format, which is decoding.
The model has Nx (shown below in figure) amounts of encoder and decoder blocks, such that the transformer’s task is to extract features from each encoder and feed them into the decoder. Positional encoding ensures that the tokens are in the right order and word-embedding/input-embedding associates similar words together. Normalization of the embedding vectors makes sure that the mean and standard deviation of the vector doesn’t shift, which may in turn negatively affect training. With a multi-head attention step in each of the blocks, we control the amount of information mixing.
GPT-1 is a transformer-based decoder-only model.

Figure. The Transformer-based Encoder-Decoder model

Figure. GPT-1 model. Transformer-based decoder-only model
Below we would like to add another variable to the language models: perplexity. Generally speaking, the lower the perplexity is, the better the language model is to predict unseen words in a test sentence. For reference, the perplexity of a unigram is 962, that of a bigram is 170, and that of a trigram is 109— where n is the number of words in a sequence of n-grams.

Function & Task
There are many tasks that GPT-1 (or GPT) was able to do: tokenization, stopword removal, and word sense disambiguation.
Tokenization is the idea of splitting words in a sequence that represents a specific idea. For example, we can say that tokenization by blanks would be counting each word as a token in English. However, there are many other, more advanced ways to tokenize.
Stopword removal is the idea of processing the input data by filtering out words that are not semantically significant.
Word sense disambiguation is the idea of taking the word given in the context, especially in situations where it is knowledge-based and not syntactical.
Generative Pre-trained Transformer 2 (GPT-2)
2019
GPT-2, the successor to GPT-1 (or GPT), saw some significant modifications. First, to encourage the diversity of content, the research group broadened the training dataset to 8 million human-curated web pages (some example pages are: Google, Archive, Blogspot, GitHub, NYTimes, Wordpress, Washington Post). Amongst the most important changes adopted by OpenAI on GPT-2 was research on potential model misuse and how to leverage greater social benefit.
Until now, previously we only discussed ReLU activation functions. Another significant change is that GPT-2 uses GeLU, the Gaussian Error Linear Unit. This cumulative distribution function uses the phi(x) function instead— x*phi(x) and not ReLU’s sigmoid function, x*sigmoid(x). Like ReLU, activation functions filter out forward propagations in the neural network. However, the GeLU’s advantage is that it weights inputs by value instead of by whether the input is positive or negative, so it prevents a “gating” or quick elimination of neurons.
Open AI addresses the fact that previously their published paper’s parameter counts are inaccurate, so small, medium models did not capture the current model’s parameter count. For example, in February 2019, the small model’s parameter count was 124M whereas the medium model’s was 345M in May. The most recent model’s parameter count is 1.5B.
Function & Task
GPT-2’s general tasks are to answer factual and non-factual questions, write short novels given supplementary information prompts, and conduct calibrated data analysis. Machine translation, summarization are some examples of GPT’s many tasks.
Based on the model card provided by OpenAI for GPT-2, the model is able to provide writing assistance such as grammar and autocompletion on normal prose or code; it is able to generate creative writing such as fictional text, poetry, and other categories of literary art; it is able to entertain the user with games, chat bots, and various other types when prompted.
GPT-2 based models such as Tabnine were launched in July 2019, and are able to complete written code.
Generative Pre-trained Transformer 3 (GPT-3)
2020
Open AI’s most recent GPT model was launched in May 2020 and was in its beta-testing stage until July 2020. Some of the new features introduced in the improved model include the concept of Byte Pair Encoding (BPE)— a method to simplify or to “compress” a string of words. Adopted into GPT-3, BPE facilitates “breaking” long and rare words into more frequently used sub-words: it is highly valuable in a limited vocabulary memory size case.
When testing autoregressive language models, another important benchmark is in-context learning performance. Researchers tested GPT-3 using zero-shot, one-shot, and few-shot metrics on GPT-3. Zero-shot means that the model can infer a specialized task, in particular, one that it is not trained to perform. One shot means that the model is given one example, and a few-shot means it is given a few examples before asked to classify/perform.
Traditionally, the model is updated every time it takes in an example task— this is called fine-tuning. However, with n-shot learning, there are only n example task input and outputs. The difficulty of arriving at the appropriate output incrementally increases as the number of example tasks decreases.
The pre-training dataset takes in Common Crawl, WebText2, Books1, Book2, and Wikipedia dataset, boasting a 410 billion BPE tokens count. Up to date, GPT-3 has 175 billion parameters, which is the largest parameter counts for any language models to date.
Function & Task
The GPT-3 language model tasks include and are not limited to, when prompted: generation of news articles, translation of human descriptions of a javascript-based website into code, demonstration of enhanced multilingual text processing from its predecessor.
On a more creative note, the model is able to compose literature in the rhetorical styles of renowned writers such as Shakespeare, Edgar Allen Poe, Ernest Hemingway. Prose, poetry, parody, puns— the model redefines our expectations of what an AI can compose. The model is able to personify notable characters in history and literature, like Cleopatra and Steve Jobs.
GPT-3 inspires a series of other softwares. Copilot, an AI pair programmer tool, uses GPT-3 as a supporting model to complete lines of code followed by user-input. In 2021, the Chinese version of a large-scale autoregressive language model was found to closely resemble GPT-3 called PanGu-Alpha.
GPT-4 is currently being developed with a predicted release date in 2023.
Game-Playing Section
The subsequent narrow AIs specialize in games— mastering a subset of rules and strategies that have proven to be effective against humans. The function and tasks of these models are to perfect the gameplay or to optimize the winning score.
AlphaGo
2016
Go is a two-player board game with the objective of enclosing the pieces of one’s opponent; the game is won when either of player resigns or the board is saturated with pieces. AlphaGo, equipped with reinforcement learning and a large database of historical winning moves, was Deepmind’s game-play model. In 2016, AlphaGo played against a world-class Go player, Lee Sedol and won 4 to 1 in the Google DeepMind Challenge Match.
AlphaGo has three neural networks, the supervised learning policy network, the reinforced learning policy network, and the value network. AlphaGo is driven by the Monte Carlo Tree Search algorithm in addition, which is a step-by-step process to maximize the expected value from each node/game state. This yields a “best” move, which is then played. Additionally, AlphaGo’s policy network suggests the moves that the model will look at, let the value network discard the moves that will have a deterministic outcome of winning or losing.
In AlphaGo, the model is given human data, domain knowledge, and known rules.

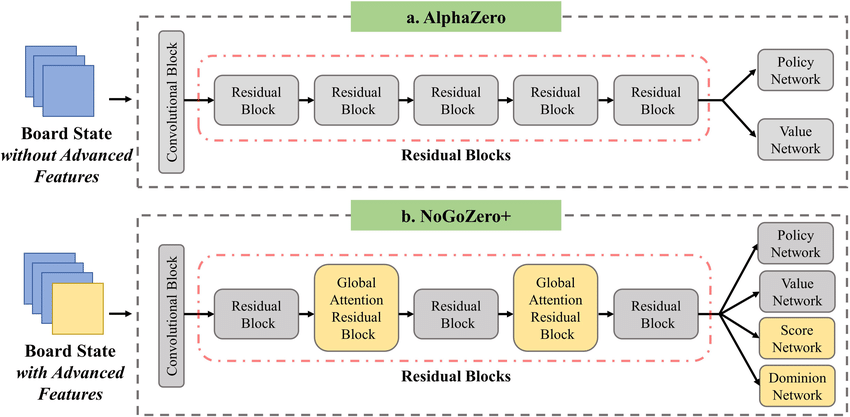
AlphaZero
2017
Deepmind’s AlphaZero expands the horizons of games that AI can master. This game-playing model was able to perfect chess, shogi, and go by self-playing using only one algorithm. Although there are in total 5064 TPUs, for the game of chess, AlphaZero only uses 4 for the game Go.
Whereas the game of Go’s board size is 19 by 19, a chess board has 64 spaces. These two games, when compared side-by-side, vary in complexity significantly. While chess has 10^120 possible game configurations, Go can have 10^174 possible configurations. Finally, Shogi has 10^224 game configurations. Shogi has a much higher gane configuration because in the game, each player has control of twenty pieces. However, once a player captures an opponent’s piece, the player can claim and use the piece.
In AlphaZero, the model is given only known rules.
MuZero
2019
MuZero was a pioneering model in the RL frontier. Researchers at Deepmind launched MuZero in 2019, introducing a model that adapts to a visually-challenging domain without any prior knowledge and achieves superhuman performance. It masters the games chess, shogi, go, and atari. The model, again, uses a learned model and tree-based search. Its performance was evaluated against all 57 Atari games, each resulting in an equal performance with its known-rules predecessor AlphaZero.
The most significant feature of MuZero was its use of implicit learning. Implicit learning is learning about the environment or the structure of the task without intention, or conscious awareness. The model was able to do this by transforming the board of Go or the screen of Atari into an input, and compute it as a hidden state. In each hidden state, the model finds the predicted move (policy network), the predicted winner (value network), and the points rewarded.
In MuZero, no previously known rules were given.
AlphaStar
2019
Starcraft II is a strategy video game that gained popularity in the 2000s. The game is one of the most played in eSports and holds annual championships. Deepmind’s expansion into a real-time and high-complexity game such as Starcraft II tests the performance of game play AI systems. Introducing AlphaStar— a model tasked with perfecting Starcraft II. The game’s difficulty comes from the fact that it requires macro-level maintenance of the working environment economy as well as the micro-level management of worker units, structures, and bases.
More specifically, AlphaStar has a large action space— there are 10 to 26 legal actions in every time step. For example, there are 16 building objects alone and one game-play usually takes an hour. The number of instances one can choose an object and build it is countless. So although it’s a strategy game, Starcraft II doesn’t have a single best strategy to be played.
MaNa, one of the strongest Starcraft II players, lost to AlphaStar 0 to 5 after the model had two weeks of training. Quoting the Deepmind page for AlphaStar, the model advantages are “superior decision-making, rather than superior click-rate, faster reaction times, or the raw interface.”

AlphaFold
2018
Protein structure prediction technology sits at the center of bioinformatics and computational biology. The protein’s function is heavily determined by its structure. Knowing this, we can modify and control the protein to perform certain functions. For example, by predicting an amino acid chain’s structure computationally, researchers have successfully produced marketed drugs. Furthermore, it is generally a good idea to understand the proteins involved at the molecular level of complex diseases.
The protein database such as the Research Collaboratory for Structurally Bioinformatics (RCSB) Protein database (PDB) provides 3D information about the protein, annotations on associated small molecules, sequence, and more. These databases are crucial in protein prediction software— like I-TASSER and RaptorX.
AlphaFold was launched by Deepmind in 2018, performing at much higher accuracy than previous models. In the Critical Assessment of Structure Prediction 2020, AlphaFold achieved a high enough accuracy to solve the problem of protein structure prediction. AlphaFold is currently open-sourced.
The AlphaFold model can predict the protein structure by taking in an amino acid sequence, looking at sequence alignment precedents, and then recycling through an Evoformer and a structure module. More specifically, the first step is to perform a multiple sequence alignment (MSA) to keep all the sequence matches. The Evoformer blocks then take the MSA representation and the 2D pair representation and deliver them to the Structure module, where the protein is folded. Recycling means that this process is being iterated 3 times until we arrive at our 3D structure.
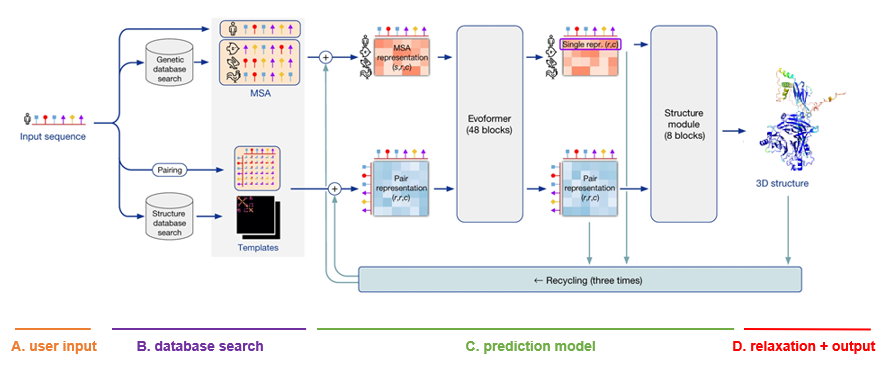
Function & Task
AlphaFold allows for protein structure prediction free to public use at extremely high accuracy. With this level of accuracy, Deepmind claims, AlphaFold and consequently AlphaFold 2 has successfully solved the protein folding problem.
Gato
2022
Deepmind introduced Gato in May 2022, a generalist agent that integrates language models capabilities, performs physical movements, annotates images, plays games like Atari and Go. Gato can perform a total of 604 trained tasks— however, some
Gato aims to test if a single agent that is versatile in multiple tasks and functions is possible, and what additional features must be implemented to make it possible. Researchers hypothesize that it is achievable once scaled to higher parameter count, a larger compute, and a bigger dataset.
Gato is a generalist agent— a model that is not specialized in one task. To truly appreciate Gato’s functions, researchers believe that there is value in building a precedent for an agent capable of combining all kinds of models. It is leading the sentiment that, if more compute and memory are granted, it will mend Gato’s shortcomings such as image annotation inaccuracies.

Function & Task
As a general purpose system, Gato is capable of performing chatbot conversations, conducting translations, finding an image to the text prompt or finding the corresponding text annotations to the image input, writing a short paragraph based on given background information, composing a poem, extracting factual information.
254 DM Lab tasks, 51 ALE Atari tasks, and 46 BabyAI tasks are some example control environment tasks that gave definite scores. A more comprehensive list of tasks is found here. In particular, Gato scored much higher on DM Lab’s 3D puzzle than the average human.
Outside of the virtual environment, it is also able to apply torque on robotic arms (joint torque), perform button presses on computer games, stack blocks by moving robotic arms.
DALL-E
2021
When Open AI’s image generator DALL-E was launched in 2021, it carried high hopes of creating futuristic art alongside channeling the public’s creativity. It is doing exactly that and more— it is an extension of GPT-3 model by transforming text into pictures.
Although Open AI has not published a paper on DALL-E specifically yet, we still are provided with its features. Its most surprising feature is the ability to perform zero-shot text-to-image generation. Zero-shot means that the model can infer a specialized task, in particular, one that it is not trained to perform.
DALL-E 2 was launched in 2022, with almost 1 million users on the product waitlist. Some newly added features include letting users import their own images to overlay variations upon a given prompt, saving generated images in the DALL-E platform, and giving users the right to commercialize the images produced by DALL-E.
Function & Task
DALL-E, according to OpenAI’s blog page, can create “anthropomorphized versions of animals and objects” in the generated pictures. Capable of transforming text that contains seemingly unrelated items within the same frame, DALL-E outputs several images with each run.
Specifically, DALL-E is able to anthropomorphize, or transfer human characteristics, onto inanimate objects. Additionally, there are certain key phrases that can prompt the model to design something in the form of another object: “in the form of” and “in the shape of” are good examples. Also, the model has the ability to adopt different fonts to various text prompts.
DALL-E 2
2022

Pathways Language Model (PaLM)
2022
Google research launched PaLM to improve language models’ performances by further scaling it. Most post-GPT models have similar improvement trends, according to the PaLM paper: scaling model depth and width, increasing training token input, intaking cleaner, and more diverse datasets all increase model capability without impinging upon computational cost.
However, PaLM takes a series of different approaches to enhance model performance. One of which is having a single model which generalizes across many domains. The pathways system is the feature that will do this— the pathways system will support workloads anticipated for future ML research that is not present in state-of-the-art models.
Function & Task
According to The Atlantic, PaLM was capable of performing “chain-of-thought prompting”. This means that the model can break down the process in which it arrived at the answer if, for example, it were to be given a math problem. PaLM has an excellent performance on the multilingual domain. If the prompt was given in one language, it will answer the question in the prompter’s language with an evaluation close to the benchmark for English. Furthermore, it is adept at source code generation either as text-to-code, code-to-code, or coding language translation.
Concluding Thoughts
After looking at these models in respective functions & tasks, we find the state-of-the-art (SOTA) race is more or less based on raw compute price reduction, more efficient architecture (LSTM to transformers, from transformers to reformers, etc.), and optimized hardware (GPU to TPU). We, therefore, hypothesize a plausible correlation between the parameter count of ML models and their capabilities & complexity.
References



Comments
Post a Comment