AGI Fundamentals: Week 1
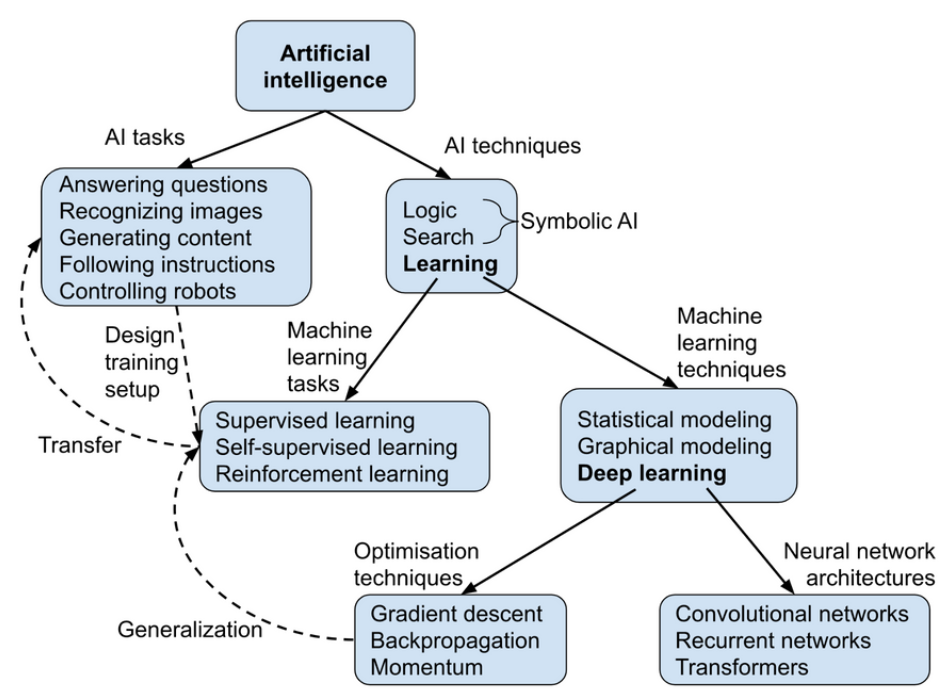
___________________________________________________________________
def Foundation models: models trained on broad data that can be adapted to a wide range of downstream tasks. Much of foundation models are enabled by transfer learning and scale. In which scale required:
1. GPU throughput and memory capacity, both increased 10x over the last four years.
2. Transformer architecture
3. availability of training data
def homogenization: all the defects of the foundation model are inherited by all the adapted models downstream.
Four Background Claims by MIRI, 2015 CE
This post aims to illustrate MIRI's mission objective.
1. Interactions between disparate modules is the general intelligence that we can not replicate in code, yet. MIRI suggests to take heed.
2. Given that the Church-Turing thesis hold, then computers can replicate the functional input/output behavior of brains as physical systems--- they might supercede soon.
3. Intellectual advantage will create incentive to gain decision-making power.
4. Compassion must be programmable. MIRI believes that highly intelligent AI won't be beneficial by default.
key motivators for AGI safety is that we will build intelligence that will achieve goals in a wide range of environments. Drexler [2019] argues that generalization-based approach will be derived from task-based approaches. Superintelligence will be derived from meta-learning.
I noticed that the Wikipedia page on Meta-learning is not updated. I have updated the ideas for the implementation and goals portion.
Duplication of an AI, termed a collective AGI by Bostom [2014], will be able to carry out significantly more complex tasks than the original. This sentiment is reliant on AGI's cultural learning capabilities, or optimizing the goal of coordinating collective intelligence.
I summarize Bostrom [2012]'s instrumental convergence thesis, which states that:
There are some instrumental goals whose attainment would increase the chances of an agent's final goals being realised for a wide range of final goals and a wide range of situations.
The four main principles of an agent are:
1. self-preservation (anti-unplug)
2. resource acquisition (anti-melting-of-GPUs)
3. technological development
4. self-improvement (recursive improvement)
And the six traits of a highly agentic AIs are:
1. Intelligence associated with first-person perspective, given that an AGI is often trained on abstract third-person data
2. elaborate planning that goes beyond myopic problem-solving
3. a consequentialist reward function
4. scale
5. coherence in decision-making, zero conflict in goal-attainment--- even if goals change over time
6. Flexibility in a multi-agent system (many AIs contribute to developing plans). AI become sphexish
Consequentialism means being able to forsee all the potential impacts of the decision. From what I understand scale means incorporating the impact of having 1 factory (for example) vs 100 factories (including the overhead it would involve, impact on the brand with having so many factories).
An example that I liked is that a highly agentic AI which has the goal of staying subordinate to humans might never take influence-seeking actions. This article read more like a literature review, a good aggregation of landmark papers like Evan Hubinger's [2019] and Scott Alexander's bioanchor.
__________________________________________________________________
Why and how of scaling LLM - Nicholas Joseph
In some of the more publically-known LLMs, 2 year compute doubling has similar behavior as Moore's law, since 2012. Since 2014, the jump increased from 10X to 300,000X. Compute is extremely important in decreasing test loss given unchanged hyperparameters in next-word prediction.
Power law is F(x) = Cx^k where C controls the intercept and k controls the slope. Compute, parameter size, and training data all follow the power law.
_[Advanced ML]_ [Future ML Systems Will Be Qualitatively Different (2022)] by Jacob Steinhardt
More is different --- Philip Anderson's argument that quantitative changes can lead to qualitatively different and unexpected phenonmena. The example he gave was that DNA, when given only a small molecules such as calcium, you can't meaningfully encode useful informaiton; given larger molecules such as DNA, you can encode a genome.
The deep learning, especially in the field of machine translation shifted from phrase-based models [https://nlp.stanford.edu/phrasal/] to neural sequence-to-sequence models [https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf] to finetuning foundation models (GPT-3 or BERT).
As parameter count increase, GPT-2's BLEU score increases linearly. It looks like emergence of new capabilities is correlated with parameter size increase--- I can infer that denoising, embed nearest k-neighbor, backtranslate are these new capabilities which are not being trained for NOR have been designed for.
Another phenonmenon is best represented graphically-- Grokking. Grokking happens when test accuracy behaves like it received an impulse, and becomes a sigmoidal curve. NN trained for 1,000 steps achieve perfect train accuracy but near-zero test accuracy. After training 100,000 steps the same NN's test accuracy increases dramatically as shown in below graphs.

pretty cool

Takeaway from Jacob Steinhardt's article:
Steinhardt says there are essentially two worldviews:
1. The engineering worldview which backpedals empirical trends and extrapolate these empirical trends forward. Did he do it by zero-th order approximation or first order approximation? Doesn't matter. Future trends will break more and more often anyways. Forecasting is not helpful in the engineering worldview.
2. The philosophy worldview thinks about the limit of very advanced systems. Thought experiments based in this worldview have a lot of weird anchors. I haven't read this yet, which talks about failure modes. It will probably be next week.
These two worldviews are similar in that misaligned objectives are an important problem with ML systems that is likely to get worse. They agree that out-of-distribution robustness is an important issue.
These two worldviews are different in that engineering worldviews tend to focus on tasks where current ML systems don't work well, weight by their impact and representativeness. I think this is saying that more impactful systems get more attention. The philosophy worldview focuses on tasks like imitative deception, or deceptive systems.



Comments
Post a Comment