Since my flight to Atlanta has been delayed for three hours, I find this time adequate for week 2: reward misspecification and instrumental convergence.
Specification gaming: the flip side of AI ingenuity.
Specification gaming is when the system's "achievement" of meeting objective without undergoing the intended outcome. Reinforcement learning agents may have been designed to getting reward without successful completion of the task delegated.
Deepmind research provides a list of existing lists of specific gaming problems.
In the Lego stacking task. The objective is to elevate the position of a piece of red lego piece, by stacking on top of a blue lego piece. The agent was reward for the height of the bottom face of the red block when it is not touching the block. Instead, the agent flipped over the red block to collect the reward.
It seems to me that it's a reward function misnomer.
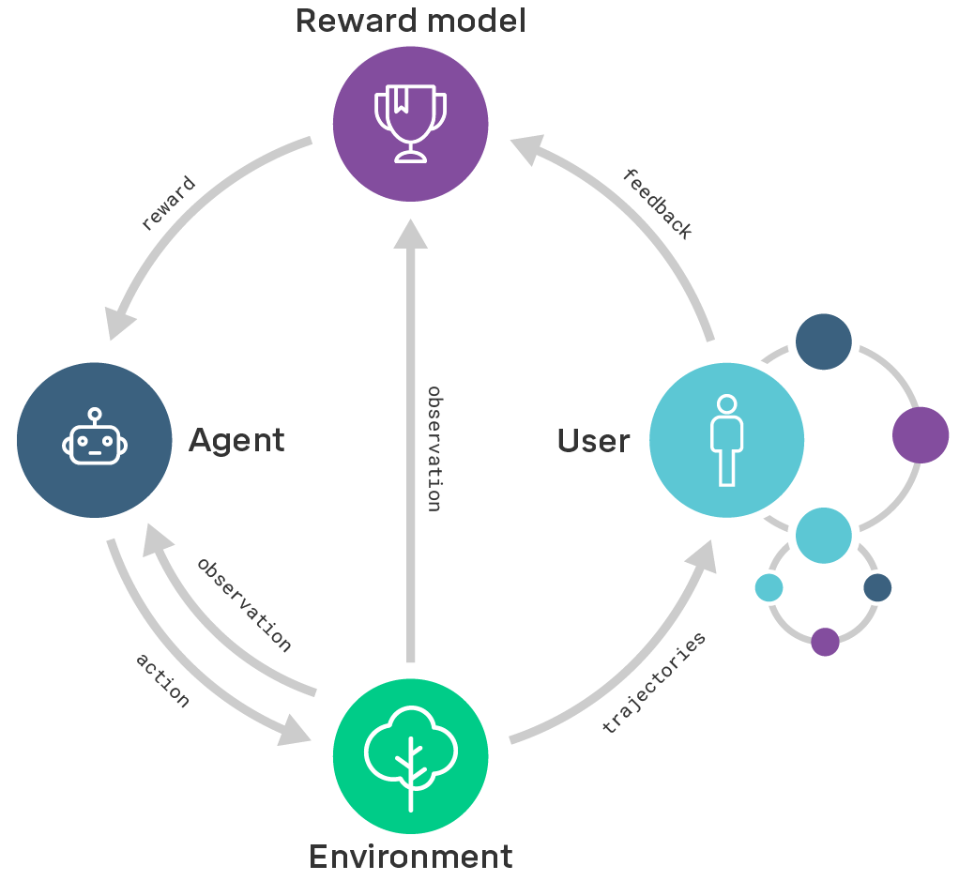
With all my talk about alignment, I understand I haven't formulated a clear definition of it. So here is my quick run-down of alignment: clear objectives in RL agents give researchers an idea which algorithmic and architecture to choose. However, the real world doesn't come with a built-reward function. How do we ensure, that the agent's policy behaves in accordance with the user's intentions? One main direction of alignment is through reward modeling, which is a separation of the reward model from the policy. Recursive reward modeling is associated with the user being a part in the evaluation process of outcomes produced by the ongoingly-trained agent.
Challenges we expect to encounter when scaling reward modeling (left) and the promising approaches to address them (right).
The alignment landscape is currently looking at Inverse Reinforcement Learning amongst other directions [http://ftp.cs.berkeley.edu/~russell/papers/colt98-uncertainty.pdf], but I am only acquainted with IRL so I will write only about it for now and learn more about the others later. IRL is gathering the decision of the human under context and arriving at the optimized reward function, as opposed to RL where the reward function and explicit goals are indicated.
Gaming systems [https://openai.com/blog/faulty-reward-functions/] are the funniest. I chuckled. [https://www.youtube.com/watch?v=K-wIZuAA3EY&t=486s]
How likely is the agent breaking out of the simulator? For it to manipulate the representation of the objective, tamper with the reward function? How do we avoid reward tampering?
TL; DR:
To solve the alignment problem, researchers identified that the root problem is from reward function misspecification or poorly designed reward shaping. RLHF and IRL are the two techniques used, but not without limitations. They suspect that these problems are likely to become more challenging to solve in the future, to specifically overcome advanced agent specification problems.
Onto "Learning from Human Preferences" by OpenAI
Instrumental convergence is the idea that AIs pursuing a range of different rewards will tend to convergence to a set of similar instrumental strategies. It's essentially saying that all reward-misspecification induced misaligned agents will converge to the same set of strategies to gain power.
Reinforcement Learning with Human Feedback, or the structure described below remove the need for humans to write goal functions, use a simple proxy for a complex goal instead. For the purpose of running a backflip model:
1. agent performs random behavior
2. two video clips are given to human
3. human makes decision which one is most similar to backflip
4. AI builds model by finding the reward function that best explains human decision
5. Reinforcement Learning until backflip is performed
example reward function for backflip:
```python
def reward_fn(a, ob):
backroll = -ob[7]
height = ob[0]
vel_act = a[0] * ob[8] + a[1] * ob[9] + a[2] * ob[10]
backslide = -ob[5]
return backroll * (1.0 + .3 * height + .1 * vel_act + .05 * backslide)
```
Learning to Summarize with Human Feedback
OpenAI published this [https://arxiv.org/abs/2009.01325] RLHF paper very recently in 2020 about how to train language models that are better at summarization, proving that generated summaries prove 10x better than 10x larger models trained only with supervised learning.
I'm curious as to how they quantified summary quality.
RLHF superceded supervised and pre-trained model of the same parameter size in human preference, comparing generated summary to control reference summaries. 1.3B RLHF outperforms 12B supervised learning model. The model picked up the traits of a good summary such as conciseness and total coverage, while having a conflicting preference for longer summaries.
These summaries were generated with the objective of mitigating failure modes such as human-imitation. For example, they are not eliciting sentences reflecting harmful social bias or making up facts when unsure.
Domains that RLHF are employed in are: dialogue, semantic parsing, translation, story and review generation, evidence extraction, etc. Summarizing the approach when generalizing onto non-Reddit source (CNN/ Daily Mail) using transfer learning--- finetuning was done on the Reddit dataset:
1. choose sample reddit post with its corresponding TL;DR
2. choose policy for the sample reddit post, generate N summaries
3. two summaries are selected from N summaries
4. a human judges which one is better
5. the judgment and the summaries are fed into the reward model
6. reward model calculates a r for each summary
7. loss is calculated based on the rewards and the human label
8. the loss is used to RL to update the reward model
9. Training the policy with PPO as a new post is sampled from the dataset
10. The policy pi generates a summary for the post
11. the reward model from step 6 calculates the reward r
12. the reward is used to iteratively update the policy via PPO
Optimizing against the reward model is expected to make policy align with human preferences. I didn't understand why varying the KL coefficient can make the reward model to get a higher reward while still retaining the incentive to remain close to the policy.
It seems to me that RLHF is the current gold standard in tasks that do not have a homogenous concensus of how the model should desirably behave, especially incorporating human feedback.
OpenAI gave one piece of statistics: their 6.7B model with RL required about 320 GPU-days compute.





Comments
Post a Comment