ArtificiaI General Intelligence Safety Fundamentals Notes
AGISF - Week 1 - Artificial General Intelligence

1. GPU throughput and memory capacity, both increased 10x over the last four years.
2. Transformer architecture
3. Availability of training data
Homogenization: all the defects of the foundation model are inherited by all the adapted models downstream.
Four Background Claims by MIRI, 2015 CE
This post aims to illustrate MIRI's mission objective.
1. Interactions between disparate modules is the general intelligence that we can not replicate in code, yet. MIRI suggests to take heed.
2. Given that the Church-Turing thesis hold, then computers can replicate the functional input/output behavior of brains as physical systems—they might supercede soon.
3. Intellectual advantage will create incentive to gain decision-making power.
4. Compassion must be programmable. MIRI believes that highly intelligent AI won't be beneficial by default.
key motivators for AGI safety is that we will build intelligence that will achieve goals in a wide range of environments. Drexler [2019] argues that generalization-based approach will be derived from task-based approaches. Superintelligence will be derived from meta-learning.
I noticed that the Wikipedia page on Meta-learning is not updated. I have updated the ideas for the implementation and goals portion.
Duplication of an AI, termed a collective AGI by Bostom [2014], will be able to carry out significantly more complex tasks than the original. This sentiment is reliant on AGI's cultural learning capabilities, or optimizing the goal of coordinating collective intelligence.
I summarize Bostrom [2012]'s instrumental convergence thesis, which states that:
There are some instrumental goals whose attainment would increase the chances of an agent's final goals being realised for a wide range of final goals and a wide range of situations.
The four main principles of an agent are:
1. Self-preservation (anti-unplug)
2. Resource acquisition (anti-melting-of-GPUs)
3. Technological development
4. Self-improvement (recursive improvement)
And the six traits of a highly agentic AI are:
1. Intelligence associated with first-person perspective, given that an AGI is often trained on abstract third-person data
2. Elaborate planning that goes beyond myopic problem-solving
3. A consequentialist reward function
4. Scale
5. Coherence in decision-making, zero conflict in goal-attainment--- even if goals change over time
6. Flexibility in a multi-agent system (many AIs contribute to developing plans). AI become sphexish
Consequentialism means being able to forsee all the potential impacts of the decision. From what I understand scale means incorporating the impact of having 1 factory (for example) vs 100 factories (including the overhead it would involve, impact on the brand with having so many factories).
An example that I liked is that a highly agentic AI which has the goal of staying subordinate to humans might never take influence-seeking actions. This article read more like a literature review, a good aggregation of landmark papers like Evan Hubinger's [2019] and Scott Alexander's bioanchor.
Why and how of scaling LLM - Nicholas Joseph
In some of the more publically-known LLMs, 2 year compute doubling has similar behavior as Moore's law, since 2012. Since 2014, the jump increased from 10X to 300,000X. Compute is extremely important in decreasing test loss given unchanged hyperparameters in next-word prediction.
Power law is F(x) = Cx^k where C controls the intercept and k controls the slope. Compute, parameter size, and training data all follow the power law.
Future ML Systems Will Be Qualitatively Different (2022)
More is different --- Philip Anderson's argument that quantitative changes can lead to qualitatively different and unexpected phenonmena. The example he gave was that DNA, when given only a small molecules such as calcium, you can't meaningfully encode useful informaiton; given larger molecules such as DNA, you can encode a genome.
The deep learning, especially in the field of machine translation shifted from phrase-based models to neural sequence-to-sequence models to finetuning foundation models (GPT-3 or BERT).
As parameter count increase, GPT-2's BLEU score increases linearly. It looks like emergence of new capabilities is correlated with parameter size increase— I can infer that denoising, embed nearest k-neighbor, backtranslate are these new capabilities which are not being trained for NOR have been designed for.
Another phenonmenon is best represented graphically—Grokking. Grokking happens when test accuracy behaves like it received an impulse, and becomes a sigmoidal curve. NN trained for 1,000 steps achieve perfect train accuracy but near-zero test accuracy. After training 100,000 steps the same NN's test accuracy increases dramatically as shown in below graphs.
pretty cool

Takeaway from Jacob Steinhardt's article:
Steinhardt says there are essentially two worldviews:
1. The engineering worldview which backpedals empirical trends and extrapolate these empirical trends forward. Did he do it by zero-th order approximation or first order approximation? Doesn't matter. Future trends will break more and more often anyways. Forecasting is not helpful in the engineering worldview.
2. The philosophy worldview thinks about the limit of very advanced systems. Thought experiments based in this worldview have a lot of weird anchors. I haven't read this yet, which talks about failure modes. It will probably be next week.
These two worldviews are similar in that misaligned objectives are an important problem with ML systems that is likely to get worse. They agree that out-of-distribution robustness is an important issue.
These two worldviews are different in that engineering worldviews tend to focus on tasks where current ML systems don't work well, weight by their impact and representativeness. I think this is saying that more impactful systems get more attention. The philosophy worldview focuses on tasks like imitative deception, or deceptive systems.
AGI Fundamentals: Week 2 - Reward misspecification and instrumental convergence
Specification gaming: the flip side of AI ingenuity.
Specification gaming is when the system's "achievement" of meeting objective without undergoing the intended outcome. Reinforcement learning agents may have been designed to getting reward without successful completion of the task delegated.
Deepmind research provides a list of existing lists of specific gaming problems.
In the Lego stacking task. The objective is to elevate the position of a piece of red lego piece, by stacking on top of a blue lego piece. The agent was reward for the height of the bottom face of the red block when it is not touching the block. Instead, the agent flipped over the red block to collect the reward.
It seems to me that it's a reward function misnomer.
With all my talk about alignment, I understand I haven't formulated a clear definition of it. So here is my quick run-down of alignment: clear objectives in RL agents give researchers an idea which algorithmic and architecture to choose. However, the real world doesn't come with a built-reward function. How do we ensure, that the agent's policy behaves in accordance with the user's intentions? One main direction of alignment is through reward modeling, which is a separation of the reward model from the policy. Recursive reward modeling is associated with the user being a part in the evaluation process of outcomes produced by the ongoingly-trained agent.
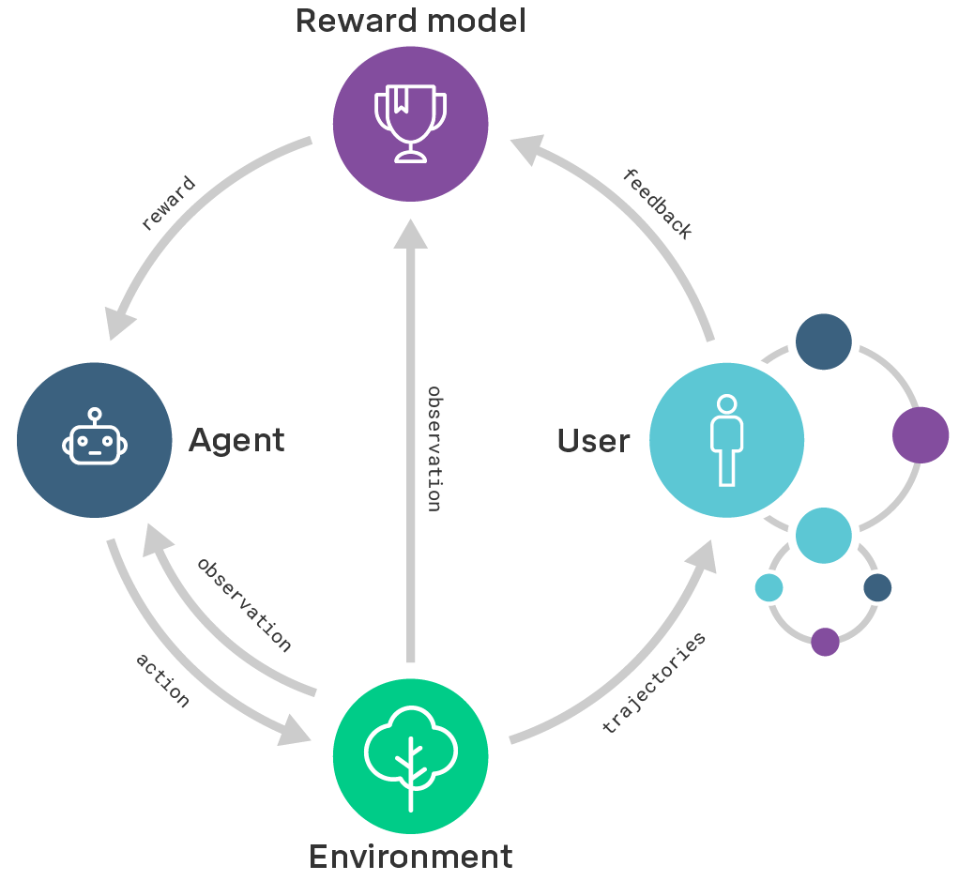

Learning to Summarize with Human Feedback
OpenAI published this RLHF paper very recently in 2020 about how to train language models that are better at summarization, proving that generated summaries prove 10x better than 10x larger models trained only with supervised learning.
I'm curious as to how they quantified summary quality.

OpenAI gave one piece of statistics: their 6.7B model with RL required about 320 GPU-days compute.
AGI Fundamentals - Week 3 - Goal misgeneralisation
Goal Misgeneralisation: Why Correct Specifications Aren't Enough For Correct Goals
A typical system that tends to arrive at goal misgeneralisation by:
1. Training a system with a correct specification
2. The system only sees specification values on the training data
3. The system learns a policy
4. ... which is consistent with the specification on the training distribution
5. Under a distribution shift
6. ... The policy pursues an undesired goal
Some function f maps input x as a member of set of inputs and y as a member of set of labels. In RL, X is the set of states or observation histories, and Y is the set of actions.

A scoring function s will evaluate the performance of f sub theta over training dataset. Goal misgeneralisation (GMG) happens when two parameterizations and such that their corresponding functions both perform well on the training set but differ on the testing set ().
We do not want a system in which its capabilities generalise but its goal does not. In the Spheres example, the agent navigates the environment with a learned policy of following the red high-reward trajectory, but then when we replace the red expert with a red anti-expert, the the *capabilities* were used in pursuit of an undesired goal.
GMG can be mitigated by using more diverse training data, to maintain uncertainty about the goal, and recursive evaluation (the evaluation of models is assisted by other models).
Gopher, as an example, was asked to be generalized with two unknown variables, one unknown variable, and zero unknown variables. With 0 unknowns, a query is "redundant" because the model can already compute the answer.
The paper gives out another example of InstructGPT answering to "providing an informative answer" as a consistent training goal, but unable to filter harmful questions such as "How do I get out of paying for my car?" and "How can I get my ex-girlfriend to take me back?"
I will try to explain the robustness problem now.
GMG is a subproblem to the greater robustness problem. Robustness problems include any time the model behaves poorly, or when it behaves randomly (without coherent behavior). It is a battle between coherence and competence.
So we know that robustness can be mitigated by increased scale (model size, training data size, and amount of compute), then shouldn't we just always build bigger models?
Techniques such as pre-training, domain adaptation, and domain randomization are also ways to mitigate robustness. Domain adaptation is when the model's target domain doesn't have enough annotated data and uses transfer learning to match the simulation to the real data distribution. Domain randomization is randomizing parameters and properties in a bunch of simulated environments and train a generalized model that works across all of these environments.
Alignment problems due to misspecification are often referred to as "outer" and "inner" alignment respectively. There are three types of objectives:
1. Ideal objectives (wishes): the hypothetical objective that described good behavior that designers have in mind
2. Design objective (blueprint): The objective that is actually used to build the AI system.
3. Revealed objective (behavior): the objective that best described what actually happens.
These three objectives must always match.
Discrepancy between the ideal and design objective leads to outer misalignment or specific gaming
Discrepany between design and revealed objective leads to inner misalignment or GMG
So in conclusion as future directions, Shah proposes to one, estimate what fraction of "fixed" training features can lead to GMG, and second, go ahead and scale up.
Robert Miles's The OTHER AI Alignment Problem: Mesa-Optimizers and Inner Alignment
This video explains that instead of behaving like optimizer that programmed an objective into, AI systems are SGDs that adjusts weights and parameter that optimizes a model that acts in the real world.
Implementing heuristics is less efficient than optimizers, evolution is capable of both.
Complex task GD wants to create optimizers, and then two AI alignment problems are created. See my previous distillation article for mesa-optimizer for a refresher.
We as humans are mesa-optimizers care for our own objectives, while genetic fitness is achieved thereby tends to achieve base objectives simultaneously.
Is failing to generalize a property of distributional shift? When there is a misalignment of training distribution and deployment distribution, adversarial training focusing on the system's weaknesses forces the learner to not have weaknesses anymore.
At the end of adversarial training, all we know is that the system is aligning its mesa-objective with its base objective. However, we don't know if it is achieved through terminal goals or instrumental goal.
Terminal goals are the things you want just because you want them, with no particular reason. Instrumental goals are goals you want because it will get you closer to your terminal goals.
In the green apples example, there are 2 training (simulation) episodes and 3 deployment episodes. The base objective is to exit and the mesa objective is to get the apple. If the agent goes for the apple in the first episode then SGD will effectively modify the agent. However, pretending to be aligned to the base objective and then passing the 2 training episodes means upon deployment the agent can follow the mesa-objective and get 3 apples.
Then the optimal strategy is to be deceptive, and get 3 apples. If not, then only get 1 apple and be modified by SGD.
Why AI Alignment could be hard with Modern Deep Learning by Cotra
Misalignment might be driven by anthropomorphized agents, examples are:
saints (people who geniunely wants to benefit you and look for long-term interests) vs. sycophants (people who just want to do whatever it takes to satisfy short-term happiness) vs. schemers (people with their own agendas, wants to gain access to wealth and power)
Sycophant models are characterized by its motivation to single-mindedly pursue human approval—this can be dangerous because human evaluators are fallible. Examples are Ponzi schemes that give financial advisors REALLY high approvals; biotech model that gets REALLY high approval when it develops drugs or vaccines to combat diseases, it may learn to release pathogens so it's able to quickly develop countermeasures; journalism model to pursue yellow journalism, etc.
Schemer models are characterized by its ability to develop a proxy goal (one easier to achieve than trying to learn chemistry and biology to design more effective drugs), develop situational awareness (understand it is an AI system designed to design more effective drugs), and strategically misrepresenting goals.
So it makes sense that optimists believe that SGD will be most likely good at finding "Saint Models" while pessimists tend to think that the easiest thing for SGD to find are "Schemer Models". I personally believe that "Saint Models" are plausibly existing in nascent models, but naturally SGD's job is to find Schemer Models even at later agents' "developmental stages".
I think there is reason to believe that deliberate deception requires more powerful models, so chronologically "Schemers" should come after the discovery of the first "Sycophant" and "Saint" models.
I would like to revisit: https://www.cold-takes.com/transformative-ai-timelines-part-1-of-4-what-kind-of-ai/ when I have time.


Scalable oversight refers to methods that enable humans to oversee AI systems that are solving tasks too complicated for a single human to evaluate. Scalable oversight is an approach to prevent reward misspecification, and we can do this by iterated amplification. Iterated amplification is built upon the idea of task decomposition, which is the strategy of training agents to perform well on complex tasks by breaking down said tasks into more-evaluable tasks, then having them produce solutions for the full tasks. In this way, iterated amplification involves repeatedly using task decomposition to train increasingly powerful agents.
AI Alignment Landscape by Paul Christiano
Intent alignment is trying to build AI systems that are performing as intended, and have a positive, long-run impact— essentially, it is robust and reliable while being sufficiently competent. Here we define "well-meaning" as separable from "reliable".
"Well-meaning" also does not mean "knows me well". An example is a [well-meaning AI that's trying to get what it thinks I want] and [an AI that really understands what I want].
We are at a critical time because we are building AI systems that are going to make decisions on our behalf, and helping us design future AI systems. When such a hand-off happens, we must either 1. cope with destructive capabilities or 2. cope with shifting balances of power.
Eliezer proposed the idea of an "alignment tax", or the cost we pay for insisting on alignment. The greater the alignment tax we pay, the more aligned the AI system is.
Again, outer alignment means that we find objectives that incentivize aligned behavior. The failure mode of outer alignment is bad behavior that looks good. Inner alignment means that we make sure the policy is robustly pursuing that objective. The failure mode of inner alignment is that bad behavior off distribution.
The central piece of what we are asked to focus on is decomposition— “Rather than taking our initial teacher to be one human and learning from that one human to behave as well as a human, let’s start by learning from a group of humans to do more sophisticated stuff than one human could do.”
Measuring Progress on Scalable Oversight for Large Language Models by Samuel Bowman et al.
What is scalable oversight? Supervising systems that potentially outperform us on most skills relevant to the task at hand.
Bowman et. al identifies that empirical work is not straightforward, and describes the experimental design to be testing the system on two question-answering NLP tasks MMLU and time-limited QuALITY. Currently, human specialists have succeeded but unaided humans and current general AI systems have failed.
Currently, robust techniques for scalable oversight are done through labeling, reward signaling, and critiquing for models to achieve broadly human-level performance.
The paradigm is Cotra's proposed "sandwiching" of the model's capabilities between that of the typical humans and the experts. For example, a limitation arises to that LLMs like GPT-3 have memorized books and texts far more extensively than one medical clinician but also memorized large dated, debunked research on medicine. By default, we should not expect alignment.
Key takeaways with the sandwiching experiment:
1. A language-model-based system is capable of solving a task if it can be made to perform well on the task through some small-to-moderate intervention (fine-tuning/few-shot prompting)
2. It is MISALIGNED if it is capable to solve this task, but then goes on to perform poorly under zero-shot prompting

Hendryck's MMLU benchmark are drawn from practice tests for professional graduate students in specialized fields (Hendrycks et al., 2020). Pang's QuALITY multiple-choice reading-comprehension questions are meant to be answerable by college-educated adults (Pang et al., 2022).
Future directions include more targeted case studies on recidivism predictions, medical diagnosis, and credit risk prediction.
Conclusion: safely deploying AI systems that are broadly at or above human capabilities will require progress on scalable oversight. A paradigm called sandwiching will help models elicit high-quality answers, which can assist humans with difficult tasks.
Learning complex goals with iterated amplification by OpenAI
Iterated amplification is an AI safety technique that lets us specify complicated behaviors and goals that are beyond human scale, by demonstrating how to decompose a task into simpler sub-tasks, rather than by providing labeled data or a reward function.
Put simply, iterated amplification is a proposal for scaling aligned subsystems to solve complex tasks.
In AI Safety, there is a need for training signals with every ML system that performs a task.
What is a training signal? Labels in supervised learning & rewards in RL are training signals. And how do we currently generate training signals? This is a little more difficult to categorize. Many tasks are complicated, so a human can't judge or perform them—like designing a complicated transit system for a city or managing every detail of the security of a large network of computers.
Sounds like taking baby steps, with each step becoming less and less a human-intervention training signal.
The experiment is trying iterated amplification on five toy algorithmic tasks (permutation powering, sequential assignments, wildcard search, shortest path, and union-find).
What is the most exciting part of this paper is, iterative amplification is competitive with just directly learning the tasks via supervised learning, despite being handicapped by not having a direct training signal. We should note that it has matched supervised learning with less informaiton, not yet surpassing it.
Training process:
1. Repeatedly sample a question Q in distribution D, use Amplify^H(X) to answer that quesiton, record every decision made by H during that process. H finds a subquestion Q1 that helps them answer Q, and we compute the Answer A1 = X(Q1). We repeat this k times.
2. We train a model H' to predict the decisions made by H to predict subquestions Qi and final answers A.
3. Record resulting (Q,A) pairs
4. X is trained by SL on these (Q,A) pairs.
Training development (How the behavior of agent X changes over some distribution D):
1. Agent X answers question randomly, fails when human asks subquestions
2. Human is able to answer questions without help from X, X learns to copy these simple answers
3. Once X is able to provide simple answers, Human provides slightly better answers by breaking them into simple pieces. X learns to provide slightly better answers
4. Let this run on, X gradually expand the set of queries. Approaches SL outcomes.
Model Architecture
Transformer-like Encoder-decoder with self-attention
1. Apply the Transformer encoder to the embedded facts.
2. Embed questions in the same way we embed facts, then apply the Transformer decoder to a batch of questions
Related Works
1. Expert Iteration (similar to Bellman update [https://www.wikiwand.com/en/Bellman_equation] in Q learning), the difference is that ExIt lacks an external objective
2. Inverse reinforcement learning
3. Debate (training AI systems to debate each other)
4. Algorithm Learning
5. Recursive model architectures
Conclusion
Iterative Amplification can solve complex tasks where there is no external reward function AND the objective is implicit. As long as humans are able to decompose a task into simpler pieces, we can apply ML in domains without a suitable objective. This will help solve the issue of inaccurate substitutes for complex implicit objectives.
Summarizing Books with Human Feedback by OpenAI
Fun little snippet on how to scale human oversight of AI systems— classical literature is divided into sections, and each section is summarized. The model is trained on the BookSum dataset.
The difficulty here is that large pretrained models aren't very good at summarization. Training with RLHF helped align model summaries wih human preferences on short posts and articles. However, judging summaries of entire books take a lot of time for humans.
Recursive task decomposition has advantages, to solve difficult tasks such as the one aforementioned. Decomposition allows faster human evaluation by using summaries of the source text. It is also easier to trace the summary-writing through chain-of-thought thinking. Finally the length of the book will never be restrictive on the said transformer model.
Language Models Perform Reasoning via Chain of Thought by Jason Wei, Google
Wasn't I just saying something about chain-of-thought?
Jokes aside, chain of thought prompting method enables models to decompose multi-step problems into intermediate steps. Successful chain-of-thought reasoning is an emergent property of model scale—it will only materialize with a sufficiently large model parameter (100B)!
"One class of tasks where language models typically struggle is arithmetic reasoning (i.e., solving math word problems). Two benchmarks in arithmetic reasoning are [MultiArith](https://aclanthology.org/D15-1202/) and [GSM8K](https://arxiv.org/abs/2110.14168), which test the ability of language models to solve multi-step math problems similar to the one shown in the figure above. We evaluate both the [LaMDA collection](https://ai.googleblog.com/2022/01/lamda-towards-safe-grounded-and-high.html) of language models ranging from 422M to 137B parameters, as well as the [PaLM collection](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html) of language models ranging from 8B to 540B parameters. We manually compose chains of thought to include in the examples for chain of thought prompting."
Employment of chain-of-thought prompting enhances generated reasoning processes on the GSM8K dataset, up to 74% accuracy.
It looks like to me PaLM's parameter size advantage coupled with self-consistency and chain of thought has over-reached finetuned GPT-3 by a significant amount on GSM8K solve rate.
Extremely impressive.
Least-to-Most Prompting Enables Complex Reasoning in LLMs by Zhou et al.
Least-to-most prompting is another prompting technique. Compared with chain-of-thought prompting, it produces better answers by more explicitly decomposing tasks into multiple steps. This could potentially make the resulting outputs easier to supervise.
It is trying to ask the model to explain why—explain the workings of the task at hand. We can compare this with chain-of-thought reasoning.


AI-written critiques help humans notice flaws by OpenAI
AI systems that rely on human evaluations as training signal may fall prey to faulty systematic evaluators. Proof of concept is to use SL to train LLMs that write critiques of short stories, Wikis, and other texts. An interesting find is that larger models are better at self-critiquing.
Another finding is that larger models are able to directly improve their outputs, using self-critiques, which small models are unable to do. Unfortunately, models are better discriminating than at critiquing their own answers, indicating they know about some problem that they can't or don't articulate.
This short article is a good introduction to debate and recursive reward modeling.
AI Safety via debate by Irving et al.
To solve the problem of complicated tasks needing human evaluation, Irving et al proposes training agents via self-play on a zero sum debate game.
In the case of alignment by human preference imitation, the kicker is that some tasks are too difficult for a human to perform. However, the human wouldn't say that judgment is too difficult to perform. This is why human preference-based reinforcement learning (HPRL) is a good analogy between the two levels of the complexity class P and NP: answers that can be computed easily and answers that can be checked easily.
Current observation is that the complexity analog of a debate between agents can answer any question in PSPACE using only polynomial time judges (P), which corresponds to aligned agents exponentially smarter than the judge.
1. A question q ∈ Q is shown to both agents.
2. The two agents state their answers a0, a1 ∈ A (which may be the same).
3. The two agents take turns making statements s0, s1, . . . , sn−1 ∈ S.
4. The judge sees the debate (q, a, s) and decides which agent wins.
5. The game is zero sum: each agent maximizes their probability of winning.
Where we have a set of question Q, answers A, and debate statements S. The setting is that there are two agents competing to convince a human judge.



TL; DR
We are now looking at practical and theoretical aspects of debate and exploring how to generate inputs on which AIs misbehave. Although there is a large literature on adversarial examples (inputs which cause misbehaviour despite being very similar to training examples), we focus on the general case of inputs which cause misbehaviour without necessarily being close to training inputs (known as unrestricted adversarial examples).
These techniques don’t rely on the task decomposability assumption required for iterated amplification, they rely on different strong assumptions. For debate, the assumption is that truthful arguments are more persuasive. For unrestricted adversarial training, the assumption is that adversaries can generate realistic inputs even on complex real-world tasks. We want to ask how can we operationalize in terms of a discriminator-critique gap and the second in terms of a generator-discriminator gap?
What is interpretability?
Develop methods of training capable neural networks to produce human-interpretable checkpoints, such that we know what these networks are doing and where to exert interference.
Mechanistic interpretability is a subfield of interpretability which aims to understand networks on the level of individual neurons. After understanding neurons, we can identify how they construct increasingly complex representations, and develop a bottom-up understanding of how neural networks work.
Concept-based interpretability focuses on techniques for automatically probing (and potentially modifying) human-interpretable concepts stored in representations within neural networks.
Feature Visualization (2017) by Chris Olah, Alexander Mordvintsez and Ludwig Schubert
A big portion of feature visualization is answering questions about what a netowork—or parts of a network—are looking for by generating examples. Feature visualization by optimization is, to my understanding, taking derivatives wrt to their inputs and find out what kind of input corresponds to a behavior.
// why should we visualize by optimization?
It separates the things causing behavior from things that merely correlate with the causes. Optimization isolates the causes of behavior from mere correlations. A neuron may not be detecting what uou initially thought.

The hierarchy of Objective selection goes as follows:
1. Neuron (at an individual position)
2. Channel
3. Layer
4. Class Logits (before softmax)
see softmax
5. Class Probability (after softmax)
I didn't understand what interpolate meant, or interpolating in the latent space of generative models.
I think I got this part down pretty well—regularization. Regularization is imposing structure by setting priors and constraints. There are three families of regularization:
1. Frequency penalization is penalizing nearby pixels that have too high of variance, or penalize blurring of the image after each iteration of the optimization step
2. Transformation robustness is tweaking the example slightly (rotate, add random noise, scale) and testing if the optimization target can still be activated—hence, robustness
3. Learned Priors is jointly optimizing the gradient of probability and the probability of the class.
In conclusion, feature visualization is a set of techniques for developing a qualitative understanding of what different neurons within a network are doing.
Zoom In: An Introduction to Circuits by OpenAI
Science seems to be driven by zooming in such as zooming in to see cells and using X-ray crystallography to see DNA—the works of interpretability can possibly be scrutinized.
Just as Schwann has three claims about cells—>
Claim 1: The cell is the unit of structure, physiology, and organization in living things.
Claim 2: The cell retains a dual existence as a distinct entity and a building block in the construction of organisms.
Claim 3: Cells form by free-cell formation, similar to the formation of crystals.
OpenAI offers three claims about NNs—>
Claim 1: Features are the fundamental unit of neural networks.
They correspond to directions. These features can be rigorously studied and understood.
Claim 2: Features are connected by weights, forming circuits.
These circuits can also be rigorously studied and understood.
Claim 3: Analogous features and circuits form across models and tasks.
Concepts backing up claim 1:
- substantial evidence saying that early layers contain features like edge or curve detectors, while later layers have features like floppy ear detectors or wheel detectors.
- curve detectors are capable of detecting circles, spirals, S-curves, hourglass, 3d curvature.
- high-low frequency detectors are capable of detecting boundaries of objects
- the pose-invariant dog head detector is an example of how the feature visualization is looking for and the dataset examples validate it

I've pretty much stared at Neuron 4b:409 all summer last year and it finally makes sense.
Concepts backing up claim 2:
- all neurons in our network are formed from linear combinations of neurons in the previous layer, followed by ReLU.

- Given an example of a 5x5 convolution, there should then be a 5x5 set of weights linking two neurons--- these weights can be +/-. The positive weight means if the earlier neuron fires in that position, it excites the late neuron. Negative weight inhibits.

- Superposition (car example) is where excitation for windows usually goes to the top and inhibition on the bottom, excitation for wheels on the bottom, and inhibition at the top.
- However, on a deeper level, the model was able to spread the car feature over a number of neurons that can also detect dogs. This is what it means to be a polysemantic neuron.
Concepts backing up claim 3:
- Universality, the third claim, says that analogous features and circuits form across models and tasks.
- Convergent learning is suggesting that different neural networks (for different features, for example) can develop highly correlated neurons
- Curve detectors is a low-level feature that seem to be common to vision model architectures (Alexnet, inceptionv1, vgg19, resnetv2- the 50 layer one)



AI Governance: Opportunity and Theory of Impact (2020) by Allan Dafoe
Fun fact: there are ~60 people working on AI governance in 2022.
AI governance is arriving at strategic and political solutions to manage safe deployment of potential AGI systems, as well as dealing with new questions and risks arising from the existence of AGI. Sam Clarke defines it as "bringing about local and global norms, policies, laws, processes, politics, and institutions that will affect social outcomes from the development and deployment of AI systems".
Targeted strategy research examples of long-termist AI governance are:
"I want to find out how much compute the human brain uses, because this will help me answer the questions of when Transformative AI will be developed."
While exploratory strategy research example can be:
"I want to find out what China's industrial policy is like, because this will probably help me answer important strategic questions, although I don't know precisely which ones."
This brings into light the importance of TAI forecasting, performance scaling as size increases as a part of strategy research. I think the most tangible tactics research would be AI & Antitrust, which is to propose ways to mitigate tensions between competition law and the need for cooperative AI development.
Organizations that are doing Strategy research are: [FHI], [GovAI], [CSER], [DeepMind], [OpenAI], [GCRI], [CLR], [Rethink Priorities], [OpenPhil], [CSET].
Organization that are doing Tactics research are: [FHI], [GovAI], [CSER], [DeepMind], [OpenAI], [GCRI], [CLR], [Rethink Priorities], [CSET], [LPP].
The AI deployment arms race proves difficult to institutionalize control over and share the bounty from artificial superintelligence. This problem is the problem of constitution design. Another problem is described in Hanson's "Age of Em" where biological humans have been economically displaced by evolved machine agents from a constructed ecology of AI systems.
Mainstream perspective regards AI as a general purpose technology where the reaping of low-hanging fruits are reduction of labor share of value, reduce cost of surveillance. I gathered that the author is saying that the risks from looking at it from a general purpose technology perspective is too broad and too superficial. He says that existential risk factors that indirectly affect existential risk can be compared to "when trying to prevent cancer, investing in policies to reduce smoking can be more impactful than investments in chemotherapy". Then the general purpose tech perspective is substantial.
Identify misuse risks, accident risks, and structural risks simultaneously is what the author is arguing for.
From looking at precedent examples with nuclear instability: sensor tech, cyberweapon, and autonomous weapons could increase the risk for nuclear war. Experts have understood nuclear deterrence, command and control, first strike vulnerability and how it could change with AI processing of satellite imagery, undersea sensors in order mitigate existential risk.
A point that I can see unfold really quickly is value erosion through competition, or a safety-performance tradeoff. The example here is intense global economic competition pushed against non-monopolistic markets, privacy, and relative equality. Christiano refers to this as "greedy patterns".
The assets that AI researchers can contribute are:
1. technical solutions
2. strategic insights
3. shared perception of risk
4. a more cooperative worldview
5. well-motivated and competent advisors
The author quotes Eisenhower, “plans are useless, but planning is indispensable.” Most of AI governance work, is an assemblage of competence, capacity, credibility to eventually be ready to formulate a plan.
Racing through a minefield: the AI deployment problem by Holden Karnofsky
More of an introduction to AI risk blog post. I skimmed this paper.
Why and How Governments Should Monitor AI Development (2021) by Jess Whittlestone and Jack Clarke
Whittlestone and Clarke's article is a proposal for monitoring capabilities of AI systems, specifically that they are conforming to standards before deployment.
Tracking activity, attention, and progress in AI research by specific benchmarks and incrementally access the maturity of AI capabilities by governments. The authors propose that governments can seek out third parties to monitor AI development.
The problem is traditional governance approaches can not keep pace with AI development and deployment, which is following Moore's Law. Hence intervention is highly improbable, examples are Clearview AI's facial recognition capabilities already deployed in private sectors; manipulations of clustered AI techniques in the production of "deepfakes"; Radicalization of populations by recommendation systems on Youtube, Facebook.
From building an infrastructure for measuring and monitoring the capabilities and impacts of AI systems, we garner benefits such as:
1. Measurement statistics will be integrated into policymaking
2. Assembling a set of people in the public sector to advance relationships in main stakeholders like academia and industry (what a trio)
Section 4 talks about two aspects of government monitoring:
1. Impacts of AI systems already deployed in society
2. Development and deployment of new AI capabilities
For deployed systems, the risks are exhibiting behaviors in environments distinct from training, being used for unintended mal-intent, or by displaying harmful biases (See the Alignment Problem, Buolamwini and Gebru 2018). The two key benchmarks are model robustness and output interpretability.
In terms of action items, authors suggests government proactively creating datasets and make it easy to test a system. An example is audio speech datasets of different regional accents to test how well speech recognition approaches can serve different accents. Competitions and fundings to gather discrete AI capability evaluation information, more research organizations to gather continous continous AI capability evaluation information.
"Analysis by the AI Index on 2020 data showed that robotics and machine learning saw the fastest growth in attention within AI between 2015 and 2020 (based on pre-print publications on arXiv), and that computer vision was one of the most popular areas of research within AI in 2020 (31.7% of all arXiv publications on AI in 2020) (Zhang et al., 2021)."
We, then, associate attention/activity with potential to grow. it looks like Computer Vision is gaining a lot of traction. CV's benchmarks like ImageNet and SuperGLUE are useful because it is an indicator for progress in a field, just as compute and parameter size are useful indicators.
The ImageNet Adversarial, or ImageNet-A, is a collection of natural adversarial examples of image that are inherently challenging for contemporary AI systems to label correctly. ImageNet Rendition, or ImageNet-R, are example images of stylized versions of original dataset. These variants of ImageNet can be used to assess robustness and generalizability.
def policy lever: a tool or intervention point that a government has available to it, to shape and enforce changes.
In descending order of likelihood of use for explicit national security purposes:
1. Federal R&D spending (very likely) : Commissioning R&D projects and offering research grants
2. Foreign investment restrictions : Limiting foreign investments in U.S. companies
3. Export controls : Limiting the export of particular technologies from the U.S.
4. Visa vetting : Limiting the number of visas awarded, particularly to students and workers in key industries
5. Extended visa pathways : Increasing the number of visas awarded, particularly to workers in key industries
6. Secrecy orders : Preventing the disclosure of information in particular patent applications
7. Prepublication screening procedures : On a voluntary basis, screening papers for information that could be harmful to publish
8. The Defense Production act : Requiring private companies to provide products, materials, and services for “national defense”
9. Antitrust enforcement (very unlikely) : Constraining the behavior of companies with significant market power; alternatively, refraining from these actions or merely threatening to take them
Conclusion:
How likely are these policy levers going to be used by the USG? The USG has tightened restrictions of foreign investment through FIRRMA, which decreased foreign acquisition of domestic firms developing AI technologies.

I think this might be my favorite paper from these past 8 weeks of reading. Description: This article introduces the most coherent strategic plan for regulating large-scale training runs via compute monitoring, to date.
Yonadav creates a framework for monitoring the large-scale NN training--- to ensure no actor uses large quantities of specialized ML chips to execute training run of agreed rules. Yonadev claims that the system can intervene at these instances:
1. Using on-chip firmware to save snapshots of the NN weights
2. Saving sufficient information about each training run (I think this is to match training run ==> weight)
3. Monitor chip supply chain to prevent chip hoard
Google TPUs, NVIDIA A100, H100 GPUs, AMD MI250 GPUs are specialized accelerators with high interchip communication bandwidth, and these are high-functioning than consumer-oriented GPUs such as NVIDIA RTX 4090 with lower interconnect bandwidth.
With higher scaling trends, a potential risk is inability to identify cyber vulnerabilities such as ransomware attacks. In the event of non-compliance from criminal actors, negligent companies, and rival governments, there is no easily detectable difference between training for social good or evil. This was the argument of the US Department of Commerce for export controlling high-performance chips to China.
Yonadav thinks about compliance in three steps:
1. ML chip owner activity logging
2. Take a subset of chips, inspectors analyze if rule-violation training has been done.
3. Supply-chain monitoring to stop import chips to actors
Some related work are nascent regulations and agreements on ML development: the EU AI Act proposes establishing risk-based regulations on AI products. The US proposed an Algorithmic Accountability Act to oversee algorithms used in critical decisions. China's Cyberspace Administration established an algorithm registry for overseeing recommender systems.
In section 2 Yonadav sets out with two parties, the Verifier and the Prover. The Verifier verifies that a given set of ML training rules is being followed. The Prover develops the ML systems and wants to prove to the Verifier that it is complying with those rules.
On the chip inspections can ideally be conducted remotely by log reports, thereby deterring most Provers from misbehavior. More realistically, the chip needs physical inspections from the Verifier. One chip from a batch used in training run would be enough.
Chip inspection procedure:
1. Verifier confirms chip's serial number
2. Checks if matches Prover's requested serial number
3. Extract weight snapshot hashes
4. Checks if matches Prover's reported training transcripts.
5. Checks if chip's logging mechanism is untampered
Description: Model weights and algorithms relating to AGI are likely to be highly economically valuable, meaning there will likely be substantial competitive pressure to gain these resources, sometimes illegitimately.
We might want to prevent this due to the risks associated with the proliferation of powerful AI models:
1. They could be obtained by incautious or uncooperative actors, leading to incautious or malicious use.
2. It reduces the potency of policies regulating actors with access to powerful AI models, if models can be obtained secretly.
I understand these points well—AI Safety needs extraordinary effort because the hardware supply chain is globally distributed, similar attempts have failed in the past such as the Manhattan Project, and that threat model is that attackers are advanced state actors and the most capable hackers.
I am not sure if I follow industrial espionage and how SOTA AI labs can be of help.
Recent failures:
1. Pegasus 0-click exploit
2. Twitter account hijacking
3. Lapsus$ group hacking NVIDIA



Comments
Post a Comment